Uncategorized
Paving a Data-Savvy Path to Ultra-High-Throughput Genomics
The All of Us project aims to enroll a million volunteers, as do the Mount Sinai Million Health Discoveries Program and the Taiwan Precision Medicine Initiative….
Share this:


The All of Us project aims to enroll a million volunteers, as do the Mount Sinai Million Health Discoveries Program and the Taiwan Precision Medicine Initiative. U.K. Biobank already has 500,000 participants and has made the entire genomes of 200,000 people available to scientists—the world’s largest single release of whole-genome sequencing (WGS) data so far. That will be followed up by the release of WGS data for another 300,000 participants in early 2023.
As large-scale genomic studies such as these spring up around the world, faster sequencing instruments are introduced, and new types of data need to be integrated, a big question is whether the analytics and storage capabilities are up to the task of making sense of all this data. Most importantly, will any of this benefit patients?
head of global software and Informatics, Illumina
Nobody is more aware of this problem than the people who make the sequencers that are churning much of this data out.
“The data is growing at a faster rate than the technology can keep up with it,” says Rami Mehio, head of global software and informatics at Illumina. Of course, Illumina is working overtime to meet this growing need, and although Rami currently sees gaps, such as the incorporation of proteomics and spatial genomics, he expects solutions will emerge quickly to help the field keep thriving.

secondary professor, department of computer and information science
co-director, Penn Program in Single Cell Biology, University of Pennsylvania
In addition, the range of data has expanded greatly. “Multiple modality data are now available for millions of cells, [and] how we integrate them will be key,” says Junhyong Kim, co-director, University of Pennsylvania Program in Single Cell Biology.
The very future of drug discovery and development is at stake. “It is very likely that the mining of data on human diversity—usingproteomics and transcriptomics, not just genetics—is going to dominate drug discovery and development,” said Kári Stefánsson, MD, Dr Med, founder and CEO of groundbreaking genomics firm deCODE, in a recent interview with our sister publication, GEN Biotechnology.
These data could also transform patient care, as Genomics England has shown (see “Clinical Applications” below). This project is slowly but steadily introducing gold-standard diagnostics and treatment of cancers throughout the U.K.’s National Health Service (NHS). It requires next-generation sequencing and the ability to analyze that and a swell of new data.
Data management advances
The field has already come a long way. For one thing, the sequencers are doing more of the data management work, automatically. Whereas a decade ago, data coming off sequencers were still images that required a lot of processing, today’s advanced instruments skip many of those steps delivering just the data that researchers need.
And for big data projects, there is now data compression, tiered storage options, and software that automatically shifts older data to cheaper storage and consolidates files that may be duplicative. Companies such as AWS, Dell, Google, IBM, and Microsoft Health (Azure) have stepped up to the plate for the flexible storage demand.
“You can imagine a precision medicine operation or diagnostic lab generating a lot of data,” Mehio explains. “They run the data and get results, leave it accessible on expensive storage for six months, then the software automatically moves it to a cheaper, though harder-to-access storage system.”
Besides updating their sequencers and software, Illumina, the leader in the sequencer instrument field, responded to the demand by acquiring Enancio, a firm that developed data-compression software for the field. “This type of compression is genomic-specific,” Mehio says. “It accounts for the duplicative parts of the genome.” There are other compression solutions, “[but] this reduces the data five-fold, without losing the critical information,” he adds.
As even higher-throughput instruments come online, and data from fields such as proteomics and spatial genomics become more widely used, analytics and storage will be further pressed.
What advice does Mehio have for anyone starting a big genomics project now?
“From the beginning, set up compression to get the smallest footprint. Find a way to store your variants in the cheapest database possible. For your big files of sequence reads you want to set up archival storage as soon as you can. You may want to access that data later, so hold onto it, but make sure it’s in a less expensive storage option,” he says.
But that is a big challenge for scientists who aren’t with big companies that have this all worked out.

co-founder and CSO, Watershed Informatics
“A variety of problems are coming to a head in this field,” says Mark Kalinich, co-founder and CSO of Watershed Informatics. “There are two major obstacles [that] prevent turning data into insight, those are [1] inaccessible computational infrastructure and [2] today’s tooling is both fragmented and fragile.”
By that, he explains, he means that wet lab scientists who generate a lot of data from sequencing need to figure out how to turn it into something interpretable. Companies need to not only determine how to store all this data but how to interpret it.
“Many of these bioinformatics tools are old, they may be incompatible” says Kalinich. “The size and variety of data in this field has been growing exponentially,” he adds. “You have a need that is not being matched with an explosion in capabilities.”
Today’s infrastructure, even if it includes the cloud, Kalinich says, although highly flexible, is not that accessible. “You can do it all in the cloud the way you could do the entire Hoover Dam in cement,” he says. “The cloud can deliver storage, but the remaining problem is the compute that is needed to charge that and the appropriate bioinformatics needed to make it productive.”
The challenge of sharing data
It’s been a touchy subject until now, because of privacy issues, but data sharing is finally coming to the fore.
The U.K. has been leading the way. U.K. Biobank is a prospective cohort study of 500,000 participants aged 40–69 years during 2006–2010. The study was established to “enable research into the lifestyle, environmental, and genomic determinants of life-threatening and disabling diseases of middle and old age.”
Data collected at recruitment included self-reported lifestyle and medical information (supplemented subsequently by antecedent information from health records), a wide range of physical measures (e.g., blood pressure, anthropometry, spirometry) and biological samples (blood, urine, and saliva). All of the data can be viewed on U.K. Biobank’s online Data Showcase, including summary statistics for each data field available for research.

founder and CEO, deCODE
“The U.K. Biobank is a very unusual enterprise. It is the biggest gift ever to biological science. They have made the data available to the entire world to work with, which is beautiful. It has turned out to be a bit more difficult for Americans to do,” says Stefánsson.
All of Us, meanwhile, released nearly 100,000 WGS sequences this March. About 50% of the data is from individuals who identify with racial or ethnic groups that have historically been underrepresented in research. The project also released data on 20,000 people who have had SARS-CoV-2.
This project includes a lot of outside data from surveys. In late 2021, All of Us launched the Social Determinants of Health Survey (SDOH) to collect information about various social and environmental factors of peoples’ everyday lives. These factors include neighborhood safety, food, and housing security, and experiences with discrimination and stress.
The COVID-19 Participant Experience (COPE) survey asked questions about the impact of COVID-19 on participants’ mental health, well-being, and everyday lives. The survey was deployed six times between May 2020 and February 2021 to help researchers understand how COVID-19 impacted participants over time.

chief data officer, All of Us Research Program
“The biggest challenge has been figuring out what to store and what to share,” says Andrea Ramirez, chief data officer of the All of Us program. “One of our goals is to make the data widely available, making the methodology transparent, but ensuring that participants’ identities are kept indistinguishable.”
Of course, sharing means a lot of data integration issues. “Multi-modal data integration requires knowing whether data are matched [i.e., measured in the same way] or unmatched,” says Kim.
Ramirez echoes that. “We bring in outside data,” she says. “But standards are not always the same. We have our own internal quality controls, but we serve such a diverse set of researchers and quality standards are not always identical.”
The ultimate goal: clinical application
Then there is the issue of moving genomics into the clinical sphere, which is the point of all this. The U.K. has also led on this front. Since 2020, Genomics England has been doing whole-genome sequencing of all pediatric cancers, sarcomas, and acute leukemia patients being treated in the U.K. National Health Service (NHS). They are now starting to sequence triple-negative breast cancer patients, gliomas, and ovarian cancers.
The project covers National Health Service Genomic Medicine Service (NHS GMS) patients. They may be offered whole-genome sequencing as part of their clinical care, and are asked if they want to donate that data and/or a biological sample for research.

chief ecosystems and partnership officer, Genomics England
Genomics England says they have the largest clinical genomics dataset in the world in cancer. “We sequence both the germline and the tumor and we do so with deep coverage, so we don’t stop sequencing until we have covered every gene,” says Parker Moss, chief ecosystems and partnership officer of Genomics England.
Half of each tumor sample is put in paraffin, then cut in slices that are digitized. The digital image of the tumor biopsy, the genomic sequence data, and any other imaging data, such as radiology, are used in combination to gauge the patient’s outlook and determine optimal treatment.
Genomic data are analyzed using specialized Natural Language Processing (NLP). Moss says, “We compress it down into a binary file, and then vectorize the image. We can then express the image as a matrix, 1000 x 1000 pixels.”
Patients whose data are being pulled into this research platform are from 80 different hospitals. So, to digitize these images entails first getting the physical slides from the hospitals and sending them to the National Pathology Imaging Cooperative (NPIC) in Leeds, Genomics England’s partners in this work. The project, Moss says, has more than 60 petabytes of mostly genomic data, but contains a growing proportion of image data.
While there are clinical centers around the globe that offer such services, Genomics England stands out in systemizing the process. Hopefully, more data sharing, new tools, and new projects will make patient services such as these truly worldwide.
Malorye Branca is a freelance science writer based in Acton, MA.
The post Paving a Data-Savvy Path to Ultra-High-Throughput Genomics appeared first on Inside Precision Medicine.
treatment genome covid-19 goldUncategorized
Part 1: Current State of the Housing Market; Overview for mid-March 2024
Today, in the Calculated Risk Real Estate Newsletter: Part 1: Current State of the Housing Market; Overview for mid-March 2024
A brief excerpt: This 2-part overview for mid-March provides a snapshot of the current housing market.
I always like to star…
Share this:

A brief excerpt:
This 2-part overview for mid-March provides a snapshot of the current housing market.There is much more in the article.
I always like to start with inventory, since inventory usually tells the tale!
...
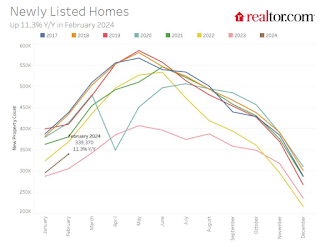
Here is a graph of new listing from Realtor.com’s February 2024 Monthly Housing Market Trends Report showing new listings were up 11.3% year-over-year in February. This is still well below pre-pandemic levels. From Realtor.com:
However, providing a boost to overall inventory, sellers turned out in higher numbers this February as newly listed homes were 11.3% above last year’s levels. This marked the fourth month of increasing listing activity after a 17-month streak of decline.Note the seasonality for new listings. December and January are seasonally the weakest months of the year for new listings, followed by February and November. New listings will be up year-over-year in 2024, but we will have to wait for the March and April data to see how close new listings are to normal levels.
There are always people that need to sell due to the so-called 3 D’s: Death, Divorce, and Disease. Also, in certain times, some homeowners will need to sell due to unemployment or excessive debt (neither is much of an issue right now).
And there are homeowners who want to sell for a number of reasons: upsizing (more babies), downsizing, moving for a new job, or moving to a nicer home or location (move-up buyers). It is some of the “want to sell” group that has been locked in with the golden handcuffs over the last couple of years, since it is financially difficult to move when your current mortgage rate is around 3%, and your new mortgage rate will be in the 6 1/2% to 7% range.
But time is a factor for this “want to sell” group, and eventually some of them will take the plunge. That is probably why we are seeing more new listings now.
Uncategorized
Pharma industry reputation remains steady at a ‘new normal’ after Covid, Harris Poll finds
The pharma industry is hanging on to reputation gains notched during the Covid-19 pandemic. Positive perception of the pharma industry is steady at 45%…
Share this:


The pharma industry is hanging on to reputation gains notched during the Covid-19 pandemic. Positive perception of the pharma industry is steady at 45% of US respondents in 2023, according to the latest Harris Poll data. That’s exactly the same as the previous year.
Pharma’s highest point was in February 2021 — as Covid vaccines began to roll out — with a 62% positive US perception, and helping the industry land at an average 55% positive sentiment at the end of the year in Harris’ 2021 annual assessment of industries. The pharma industry’s reputation hit its most recent low at 32% in 2019, but it had hovered around 30% for more than a decade prior.
“Pharma has sustained a lot of the gains, now basically one and half times higher than pre-Covid,” said Harris Poll managing director Rob Jekielek. “There is a question mark around how sustained it will be, but right now it feels like a new normal.”
The Harris survey spans 11 global markets and covers 13 industries. Pharma perception is even better abroad, with an average 58% of respondents notching favorable sentiments in 2023, just a slight slip from 60% in each of the two previous years.
Pharma’s solid global reputation puts it in the middle of the pack among international industries, ranking higher than government at 37% positive, insurance at 48%, financial services at 51% and health insurance at 52%. Pharma ranks just behind automotive (62%), manufacturing (63%) and consumer products (63%), although it lags behind leading industries like tech at 75% positive in the first spot, followed by grocery at 67%.
The bright spotlight on the pharma industry during Covid vaccine and drug development boosted its reputation, but Jekielek said there’s maybe an argument to be made that pharma is continuing to develop innovative drugs outside that spotlight.
“When you look at pharma reputation during Covid, you have clear sense of a very dynamic industry working very quickly and getting therapies and products to market. If you’re looking at things happening now, you could argue that pharma still probably doesn’t get enough credit for its advances, for example, in oncology treatments,” he said.
vaccine pandemic covid-19Uncategorized
Q4 Update: Delinquencies, Foreclosures and REO
Today, in the Calculated Risk Real Estate Newsletter: Q4 Update: Delinquencies, Foreclosures and REO
A brief excerpt: I’ve argued repeatedly that we would NOT see a surge in foreclosures that would significantly impact house prices (as happened followi…
Share this:

{kind=link}
A brief excerpt:
I’ve argued repeatedly that we would NOT see a surge in foreclosures that would significantly impact house prices (as happened following the housing bubble). The two key reasons are mortgage lending has been solid, and most homeowners have substantial equity in their homes..There is much more in the article. You can subscribe at https://calculatedrisk.substack.com/ mortgage rates real estate mortgages pandemic interest rates
...
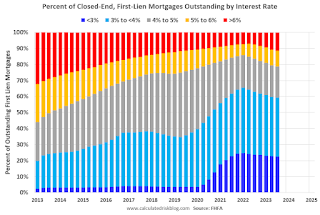
And on mortgage rates, here is some data from the FHFA’s National Mortgage Database showing the distribution of interest rates on closed-end, fixed-rate 1-4 family mortgages outstanding at the end of each quarter since Q1 2013 through Q3 2023 (Q4 2023 data will be released in a two weeks).
This shows the surge in the percent of loans under 3%, and also under 4%, starting in early 2020 as mortgage rates declined sharply during the pandemic. Currently 22.6% of loans are under 3%, 59.4% are under 4%, and 78.7% are under 5%.
With substantial equity, and low mortgage rates (mostly at a fixed rates), few homeowners will have financial difficulties.
{kind=link}


Q4 Update: Delinquencies, Foreclosures and REO


Pharma industry reputation remains steady at a ‘new normal’ after Covid, Harris Poll finds


Part 1: Current State of the Housing Market; Overview for mid-March 2024


Digital Currency And Gold As Speculative Warnings


Bougie Broke The Financial Reality Behind The Facade


Futures Flat At All-Time High As Bitcoin Surges To Record, Oil Rises


The most potent labor market indicator of all is still strongly positive


‘Bougie Broke’ – The Financial Reality Behind The Facade


Bitcoin on Wheels: The Story of Bitcoinetas
-

 Uncategorized3 weeks ago
Uncategorized3 weeks agoAll Of The Elements Are In Place For An Economic Crisis Of Staggering Proportions
-

 International5 days ago
International5 days agoEyePoint poaches medical chief from Apellis; Sandoz CFO, longtime BioNTech exec to retire
-

 Uncategorized4 weeks ago
Uncategorized4 weeks agoCalifornia Counties Could Be Forced To Pay $300 Million To Cover COVID-Era Program
-

 Uncategorized3 weeks ago
Uncategorized3 weeks agoApparel Retailer Express Moving Toward Bankruptcy
-

 Uncategorized4 weeks ago
Uncategorized4 weeks agoIndustrial Production Decreased 0.1% in January
-

 International5 days ago
International5 days agoWalmart launches clever answer to Target’s new membership program
-

 Uncategorized4 weeks ago
Uncategorized4 weeks agoRFK Jr: The Wuhan Cover-Up & The Rise Of The Biowarfare-Industrial Complex
-

 Uncategorized3 weeks ago
Uncategorized3 weeks agoGOP Efforts To Shore Up Election Security In Swing States Face Challenges